


一、简介
awk是逐行处理的,当awk处理一个文本时,会一行一行进行处理,处理完当前行,再处理下一行,awk默认以”换行符”为标记,识别每一行,新的一行的开始,awk会按照用户指定的分割符去分割当前行,如果没有指定分割符,默认使用空格作为分隔符
从字面上理解 ,action指的就是动作,awk擅长文本格式化,并且将格式化以后的文本输出,所以awk最常用的动作就是print和printf
二、基本语法格式
格式: awk [options] 'Pattern{Action}' file
举例: awk -F":" 'NR==5{ print $1,$2,$NF,"自定义添加字段" }' 文件
选项:
三、Pattern模式
AWK 包含两种特殊的模式:BEGIN 和 END
BEGIN 模式指定了处理文本之前需要执行的操作
END 模式指定了处理完所有行之后所需要执行的操作
举例:
处理文本前先输出aaa bbb
# awk -F":" 'BEGIN{ print "aaa","bbb" }' passwd
aaa bbb
输出后对文本进行处理
# awk -F":" 'BEGIN{ print "aaa","bbb" } NR==1{ print $1,$3}' passwd
aaa bbb
root 0
文本处理结束后进行的动作
# awk -F":" 'BEGIN{ print "aaa","bbb" } NR==1{ print $1,$3} END{ print "ccc","ddd" }' passwd
aaa bbb
root 0
ccc ddd
由此看来,最终的返回结果很像一张表,有 "表头","表内容","表尾"
# awk -F":" 'BEGIN{ print "表的头部" } NR==1{ print $1,$3} END{ print "表的尾部" }' passwd
表的头部
root 0
表的尾部
添加了printf格式化处理
# awk -F":" 'BEGIN{ printf "%s\t\t %s\n" , " ","头部" }BEGIN{ printf "%-10s\t %-10s\t %-5s\n","name","UID","SHELL" }{ printf "%-10s\t %-10s\t %-5s\n", $1,$3,$NF } END{ printf "%s\t\t %s\n", " ","尾部" }' passwd
四、分隔符
awk分为输入分隔符FS和输出分隔符OFS
输入分隔符
awk逐行处理文本的时候,以输入分隔符为准,将文本切成多个片段,默认使用空格,也可以指定使用":"作为输入分隔符
# awk -F":" 'NR==1{ print $1,$3 }' passwd
root 0
除了使用 -F 选项指定输入分隔符,还能够通过设置内部变量的方式,指定awk的输入分隔符
awk内置变量FS可以用于指定输入分隔符,但是在使用变量时,需要使用-v选项,用于指定对应的变量
# awk -v FS=":" 'NR==1{ print $1,$3 }' passwd
root 0
回顾一下我们awk的格式
# awk [options] 'Pattern{Action}' file
-F 就是options的一种,用于指定输入分隔符
-v 也是options的一种,用于设置变量的值
输出分隔符
awk输出每一列的时候,会使用空格隔开每一列,其实,这个空格,就是awk的默认的输出分隔符
可以使用awk的内置变量OFS来设定awk的输出分隔符,当然,使用变量的时候要配合使用-v选项
# awk -v FS=":" -v OFS="---" 'NR==1{ print $1,$3 }' passwd
root---0
当打印多列的时候,需要用逗号隔开才能指定输出分隔符,如果没有逗号,两列将会合并在一起显示
# awk -v FS=":" -v OFS="---" 'NR==1{ print $1$3 }' passwd
root0
# awk -v FS=":" -v OFS="---" 'NR==1{ print $1 $3,$NF }' passwd
root0---/bin/bash
五、awk变量
FS:输入字段分隔符, 默认为空白字符
OFS:输出字段分隔符, 默认为空白字符
NR:行号,当前处理的文本行的行号
NF:number of Field,当前行的字段的个数(即当前行被分割成了几列),字段数量
RS:输入记录分隔符(输入换行符), 指定输入时的换行符
ORS:输出记录分隔符(输出换行符),输出时用指定符号代替换行符
FNR:各文件分别计数的行号
FILENAME:当前文件名
ARGC:命令行参数的个数
ARGV:数组,保存的是命令行所给定的各参数
内置变量NR
显示文本的行数
# awk -F":" '{ print NR }' passwd
1
2
3
4
5
# awk -F":" 'NR==2{ print NR,$0 }' passwd
2 bin:x:1:1:bin:/bin:/sbin/nologin
内置变量NF
文本一共有几行,每一行有几列
# awk -F":" '{ print NR,NF }' passwd
1 7
2 7
3 7
4 7
5 7
内置变量FNR
当awk处理两个文本时
# awk -F":" '{ print NR,$1 }' passwd /etc/passwd
1 root
2 bin
3 daemon
4 adm
5 lp
6 root
7 bin
8 daemon
9 adm
10 lp
# awk -F":" '{ print FNR,$1 }' passwd /etc/passwd
1 root
2 bin
3 daemon
4 adm
5 lp
1 root
2 bin
3 daemon
4 adm
5 lp
内置变量FILENAME
# awk -F":" '{ print FILENAME,FNR,$1 }' passwd /etc/passwd
passwd 1 root
passwd 2 bin
passwd 3 daemon
passwd 4 adm
passwd 5 lp
/etc/passwd 1 root
/etc/passwd 2 bin
/etc/passwd 3 daemon
/etc/passwd 4 adm
/etc/passwd 5 lp
内置变量RS
RS是输入行分隔符,如果不指定,默认的”行分隔符”就是我们所理解的"回车换行"
# vim test.txt
aaa bbb ccc ddd
tom jerry zhangsan lisi
每次遇到一个空格就是新的一行,对于tom为回车换行,但是awk并不认为是换行符,只有空格才是换行符,在awk眼中,4 ddd\ntom为同一行
# awk -v RS=" " '{ print NR,$0 }' test.txt
1 aaa
2 bbb
3 ccc
4 ddd
tom
5 jerry
6 zhangsan
7 lisi
内置变量ORS
awk默认把"回车换行 "当做" 输出行分隔符,但是我们可以改变默认的输出行分隔符为+++,在awk眼中,+++就是输出换行符
# awk -v RS=" " -v ORS="+++" '{ print NR,$0 }' test.txt
1 aaa+++2 bbb+++3 ccc+++4 ddd
tom+++5 jerry+++6 zhangsan+++7 lisi
内置变量ARGV和ARGC
ARGV内置变量表示的是一个数组,这个数组中保存的是命令行所给定的参数
# awk -F":" 'BEGIN{ print ARGV[0],ARGV[1],ARGV[2] }' passwd /etc/passwd
awk passwd /etc/passwd
ARGV[0] 表示的是awk本身
ARGV[1] 第一个文件名
ARGV[2] 第二个文件名
上述例子中三个参数为awk、passwd、/etc/passwd,这三个参数作为数组的元素存放于ARGV中,而ARGC则表示参数的数量,也可以理解为ARGV数组的长度
# awk -F":" 'BEGIN{ print ARGV[0],ARGV[1],ARGV[2],ARGC }' passwd /etc/passwd
awk passwd /etc/passwd 3
自定义变量
方法一:-v varname=value 变量名区分字符大小写
例:
# awk -v i=1 'BEGIN{ print i }'
方法二:在program中直接定义,变量定义与动作之间需要用分号";"隔开
例:
# awk 'BEGIN{ i=1 ; j=2 ; print i"\n"j }'
1
2
六、正则模式
格式:
# awk '/正则表达式/{ print $0 }' passwd
匹配以root开头,打印所有的列
# awk '/^root/{ print $0}' passwd
root:x:0:0:root:/root:/bin/bash
匹配以/bin/bash结尾,打印所有的列,需要对/进行转义\
# awk '/\/bin\/bash$/{ print $0}' passwd
root:x:0:0:root:/root:/bin/bash
tom:x:1000:1000::/home/tom:/bin/bash
jerry:x:1001:1001::/home/jerry:/bin/bash
zhangsan:x:1002:1002::/home/zhangsan:/bin/bash
lisi:x:1003:1003::/home/lisi:/bin/bash
关系运算符
< 小于 x < y
<= 小于等于 x <= y
== 等于 x == y
!= 不等于 x != y
>= 大于等于 x >= y
> 大于 x > y
# awk 'NR>=2 && NR<=5{ print NR,$0}' passwd
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
七、awk动作
第一部分: '{ }' 属于 "组合语句" 类型的动作,顾名思义,"组合语句" 类型的动作的作用就是将多个代码组合成代码块
第二部分:print $0 属于 "输出语句" 类型的动作,作用就是输出、打印信息
例如:
# awk -F":" '{ print $1 }{ print $2 }' passwd 等价于 # awk -F":" '{ print $1 ; print $2 }' passwd
if判断
例如
# awk -F":" '{ if(NR==1){ print $1 } }' passwd
与awk的模式用法一样
# awk -F":" 'NR==1{ print $1 }' passwd
那如果是if else的写法呢
# awk -F":" '{ if($3 < 1000){ print $1,"系统用户" } else{print $1,"普通用户"} }' passwd
那如果是if...else if...else 的写法呢
# cat score.txt
姓名 成绩
张三丰 88
李四年 72
王五毒 96
汤姆 58
杰瑞 66
ansible 150
# awk 'NR != 1{ if($2 > 100){ print $1,"逆天" } else if( $2 > 90 && $2 <=100 ){ print $1,"优秀" } else if( $2 >= 80 && $2 <90 ){ print $1,"良好" } else if( $2 >= 60 && $2 < 80 ){ print $1,"及格" } else{ print $1,"不及格" } }' score.txt
张三丰 良好
李四年 及格
王五毒 优秀
汤姆 不及格
杰瑞 及格
ansible 逆天
for循环
# awk 'BEGIN{ for( i=1;i<=6;i++ ){ print i } }'
1
2
3
4
5
6
# awk 'BEGIN{ for( i=1;i<=6;i++ ) { if(i==3){continue}; print i } }'
1
2
4
5
6
# awk 'BEGIN{ for( i=1;i<=6;i++ ) { if(i==3){break}; print i } }'
1
2
# awk 'BEGIN{ for( i=1;i<=6;i++ ) { if(i==3){exit}; print i } }'
1
2
while循环
# awk -v i=1 'BEGIN{ while(i<5) { print i;i++ } }'
# awk 'BEGIN{ i=1;while(i<5) { print i;i++ } }'
1
2
3
4
do…while循环
它与while循环的不同之处在于,while循环只有当满足条件时才会执行对应语句,而do…while循环则是无论是否满足条件,都会先执行一遍do对应的代码,然后再判断是否满足while中对应的条件,满足条件,则执行do对应的代码,如果不满足条件,则不再执行do对应的代码
# awk 'BEGIN{ i=1;do{ print i;i++ } while(i<5)}'
# awk -v i=1 'BEGIN{ do{ print i;i++ } while(i<5)}'
1
2
3
4
next 跳过这一行
awk是逐行对文本进行处理的,也就是说,awk会处理完当前行,再继续处理下一行,那么,当awk需要处理某一行文本的时候,我们能不能够告诉awk :"不用处理这一行了,直接从下一行开始处理就行了"
# head -3 passwd | awk -F":" '{ if( $3 == 0 ){ next } print $0 }'
八、内置函数(部分)
算数函数
rand函数、srand函数、int函数
可以使用rand函数生成随机数,但是使用rand函数时,需要配合srand函数,否则rand函数返回的值将一直不变
# awk 'BEGIN{ print rand() }'
0.237788
# awk 'BEGIN{ print rand() }'
0.237788
如果单纯的使用rand函数,生成的值是不变的,可以配合srand函数,生成一个大于0小于1的随机数
# awk 'BEGIN{srand(); print rand() }'
0.613538
# awk 'BEGIN{srand(); print rand() }'
0.415389
# awk 'BEGIN{srand(); print rand() }'
0.726018
生成的随机数都是小于1的小数,如果我们想要生成整数随机数,可以将随机数乘以100,然后截取整数部分,使用int函数可以截取整数部分的值
# awk 'BEGIN{srand(); print 1000*rand() }'
179.079
[root@ansible1 ~]# awk 'BEGIN{srand(); print int(1000*rand()) }'
604
字符串函数
gsub函数与sub函数、length函数
gsub函数
将passwd文件第一行的所有的列中的r换成R(默认所有的列$0)
# awk -F":" 'NR==1{ gsub("r","R") ; print $0 }' passwd
Root:x:0:0:Root:/Root:/bin/bash
将passwd文件第一行的第一列中的r换成R
# awk -F":" 'NR==1{ gsub("r","R",$1) ; print $0 }' passwd
Root x 0 0 root /root /bin/bash
gsub会替换指定范围内的所有符合条件的字符
sub函数只会替换指定范围内第一次匹配到的符合条件的字符
sub函数
# awk -F":" 'NR==1{ sub("r","R",$0) ; print $0 }' passwd
Root:x:0:0:root:/root:/bin/bash
length函数
# awk -F":" 'NR==1{ print $1,length($1) }' passwd
root 4
找出字符长度为4的所有用户
# awk -F":" '{ if( length($1)==4 ){ print $1 } }' passwd
root
sync
halt
mail
dbus
sshd
九、printf
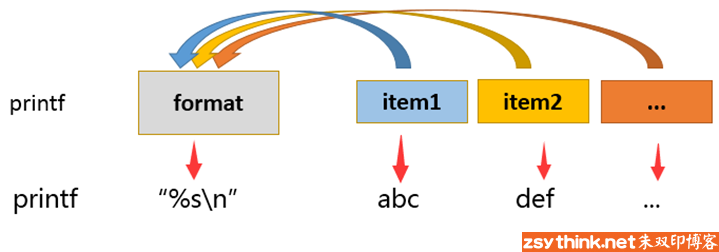
print用于输出文本,printf的优势在于格式化输出文本
echo默认换行输出
# echo -e "hello \nansible \nopenstack \ndocker \nkvm"
hello
ansible
openstack
docker
kvm
# printf "hello \nansible \nopenstack \ndocker \nkvm\n"
hello
ansible
openstack
docker
kvm
# printf format item1 item2 item3 ...
# printf "%s\n" hello ansible openstack docker kvm
hello
ansible
openstack
docker
kvm
# printf "(%s)" hello ansible openstack docker kvm
格式替换符
%s 字符串
%f 浮点格式(也就是我们概念中的float或者double)
%b 相对应的参数中包含转义字符时,可以使用此替换符进行替换,对应的转义字符会被转义。
%c ASCII字符。显示相对应参数的第一个字符
%d, %i 十进制整数
%o 不带正负号的八进制值
%u 不带正负号的十进制值
%x 不带正负号的十六进制值,使用a至f表示10至15
%X 不带正负号的十六进制值,使用A至F表示10至15
%% 表示”%”本身
转义字符
\a 警告字符,通常为ASCII的BEL字符
\b 后退
\c 抑制(不显示)输出结果中任何结尾的换行字符(只在%b格式指示符控制下的参数字符串中有效),而且,任何留在参数里的字符、任何接下来的参数以及任何留在格式字符串中的字符,都被忽略
\f 换页(formfeed)
\n 换行
\r 回车(Carriage return)
\t 水平制表符
\v 垂直制表符
\\ 一个字面上的反斜杠字符,即”\”本身。
\ddd 表示1到3位数八进制值的字符,仅在格式字符串中有效
\0ddd 表示1到3位的八进制值字符
# printf "(%s)" hello ansible openstack docker kvm ;echo ""
(hello)(ansible)(openstack)(docker)(kvm)
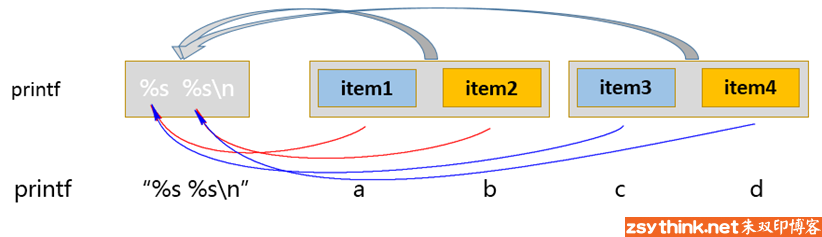
# printf "%s %s %s\n" hello ansible openstack docker kvm ELK
hello ansible openstack
docker kvm ELK
# printf "%-8s %-10s %s\n" hello ansible openstack docker kvm ELK
hello ansible openstack
docker kvm ELK
结合BEGIN和END使用
awk -F":" 'BEGIN{ printf "%-20s\t %-20s\n", "用户名称","用户ID" }{ printf "%-20s\t %-20s\n",$1,$3 } END{ print "用户一共"NR"人" }' passwd
用户名称 用户ID
root 0
bin 1
daemon 2
adm 3
lp 4
用户一共5人

